
Курс
SQL в регулярной работе джедая
У нас в it-agency работа джедая тесно связана с обработкой и анализом данных, часть которых хранится в БД. Данные нужно вытягивать, добавлять, обрабатывать. Какие-то сложные технические действия делают разработчики, а простые операции и запросы джедай должен уметь делать сам, например — наполнить базу данных, внести правки, пересечь таблички для последующего анализа.
Если вы в своей работе можете вытягивать нужные данные из БД, то это сильно упростит вашу жизнь, как маркетолога-аналитика.
Недавно прошел курс по sql на udemy, составил небольшую шпаргалку и добавил то, чем сам часто пользуюсь.

Базовые команды
SELECT — какую информацию хотим выбрать.
FROM — откуда нужно взять информацию.
Пример: Select * FROM products
выбрать всё из таблицы products.
Можно выбирать конкретные столбцы
//Пример: Select CustomerName from Customers
выбрать столбец CustomerName из таблицы Customers.
WHERE — правило по которому нужно получить данные.
Примеры:
Select * from products where Price>20
выбрать все строки из таблицы products, где в столбце Price значение больше 20.
Select * from Customers where Country=«Germany»
выбрать все строки из таблицы Customers, где в столбце Country значение = Germany.
Select * from Customers where Country LIKE ‘%Ger%’
выбрать все строки из таблицы Customers, где в столбце Country значение ячейки содержит Ger.
Select * from Customers where Country <> «Ger»
выбрать все строки из таблицы Customers, где в столбце Country значение ячейки не равняется Ger.
JOIN — объединение разных таблиц в одну.
Пример
select *
from Customers
join orders on orders.customerid = customers.customerid
where country = «Germany»
Выбрать все столбцы из таблицы Customers и объединить с таблицей orders, пересечь их условием данные в столбце orders.customerid = данным столбце customers.customerid.
Group by НазваниеСтолбца — группирует результат по уникальным значениям в столбце.
Order by НазваниеСтолбца — сортирует всю таблицу по возрастанию, если добавить desc (Order by desc), то отсортирует по убыванию.
Count() — возвращает(считает) число строк.
Пример:
SELECT COUNT(*) FROM Universities WHERE Location = 'Moscow'
Подсчитать все строки из таблицы Universities, где есть в столбце Location значение Moscow.
INSERT — команда для добавления новых данных в таблицу.
Пример:
INSERT INTO GaGoals VALUES
(1, N'60 секунд'),
(2, N'Скролл 75%'),
(3, N'Заявка отправлена'),
(4, N'Просмотр 5 и более страниц')
Добавляет в таблицу GaGoals значения. В таблице в столбце, в скобках через запятую указываются значения которые записываем в каждую строку.
N ставится перед значением, которое пишется кириллицей, чтобы оно корректно вписалось в БД и не слетела кодировка. После каждой строки, кроме последней, ставим запятую.
UPDATE — команда для обновления значения в ячейке.
Синтаксис
UPDATE НазваниТаблицыГдеВносимПравки SET НазваниеСтолбца= 'НовоеЗначение' WHERE УсловиеПоКоторомуМыОпределимНужнуюЯчейку
Пример:
UPDATE [Segments] SET [ProfileID]='1' WHERE [Id]=1001
UPDATE [Segments] SET [ProfileID]='2' WHERE [Id]=1002
UPDATE [Segments] SET [ProfileID]='3' WHERE [Id]=1003
UPDATE [Segments] SET [ProfileID]='4' WHERE [Id]=1004
UPDATE [Segments] SET [ProfileID]='5' WHERE [Id]=1005
Обновляем таблицу Segments, устанавливаем значение для столбца ProfileID = 1-5 для тех ячеек, где значение в столбце id принимает значение 1001-1005.
Если в ячейку нужно записать данные с кавычками, то их нужно экранировать кавычками.
Пример
UPDATE [Segments] SET [Segment]='ga=''test''' WHERE [Id]=1001
Обновить таблицу Segments и поставить в столбце Segment значение ga='test' для тех ячеек, где значение в столбце Id = 1001
Закончил курс Маркетинговой аналитики на Курсере
Курс от University of Virginia. Ведет профессор-практик Rajkumar Venkatesan, работающий в Bank of America.
Заняло 5 недель по 2-3 часа в неделю.
Получил 86,8 баллов из 100.
Одна из первых фраз лектора:
«Бюджет средней маркетинговой кампаний можно снизить на 20% без потери ROI»
Курс дает фундаментальные знания в области маркетингового анализа данных.
Блоки, которые мне запомнились больше всего
Модели атрибуции — как одни каналы продаж могут влиять на другие каналы, при этом напрямую не генерируя прибыль для компании.
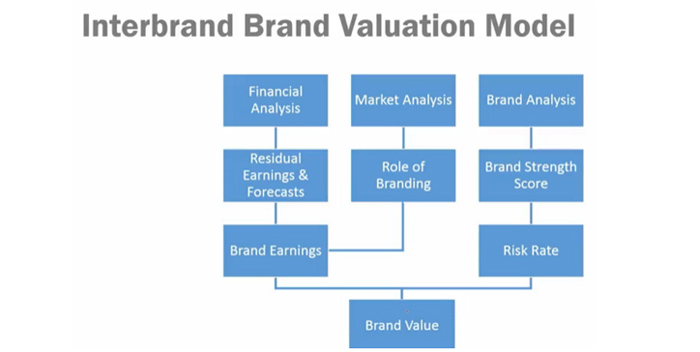
Архитектура бренда и его персоналия — из чего строится бренд и то, как воспринимают его покупатели.

Оценка стоимости бренда — дает ответ на вопрос о том, как вычисляется денежная стоимость бренда, например, как рассчитать, что Билайн стоит 155 млрд руб.
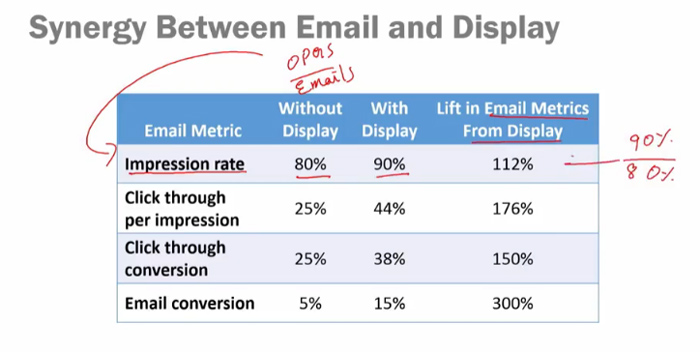
Расчёт CLV (LTV) — сколько выручки приносит 1 средний клиент за всё время контакта с компанией.
Регрессионный анализ — общие принципы и основы распределения и построения зависимостей. Например, это нужно для того, чтобы понять, как влияет наличие рекламных баннеров перед входом в магазин на продажи определенного товара.

Проведение маркетинговых экспериментов — как корректно провести рекламный эксперимент для выявления нужных закономерностей.
На что обратить внимание
После каждого блока идут тесты. Ещё будет два письменных задания, где вас привлекут для оценки работ других участников курса, они же будут оценивать и ваши работы. Весь курс на английском. Для успешного прохождения требуется как минимум средний уровень владения языком. У меня периодически возникали сложности с переводом экономических терминов, поэтому не всегда понимал вопросы в тестах и приходилось их пересдавать.
Итог
Супер-практических навыков после прохождения курса вы не получите, но в качестве основы для понимания роли и принципов аналитики в маркетинге — это очень хороший курс.